
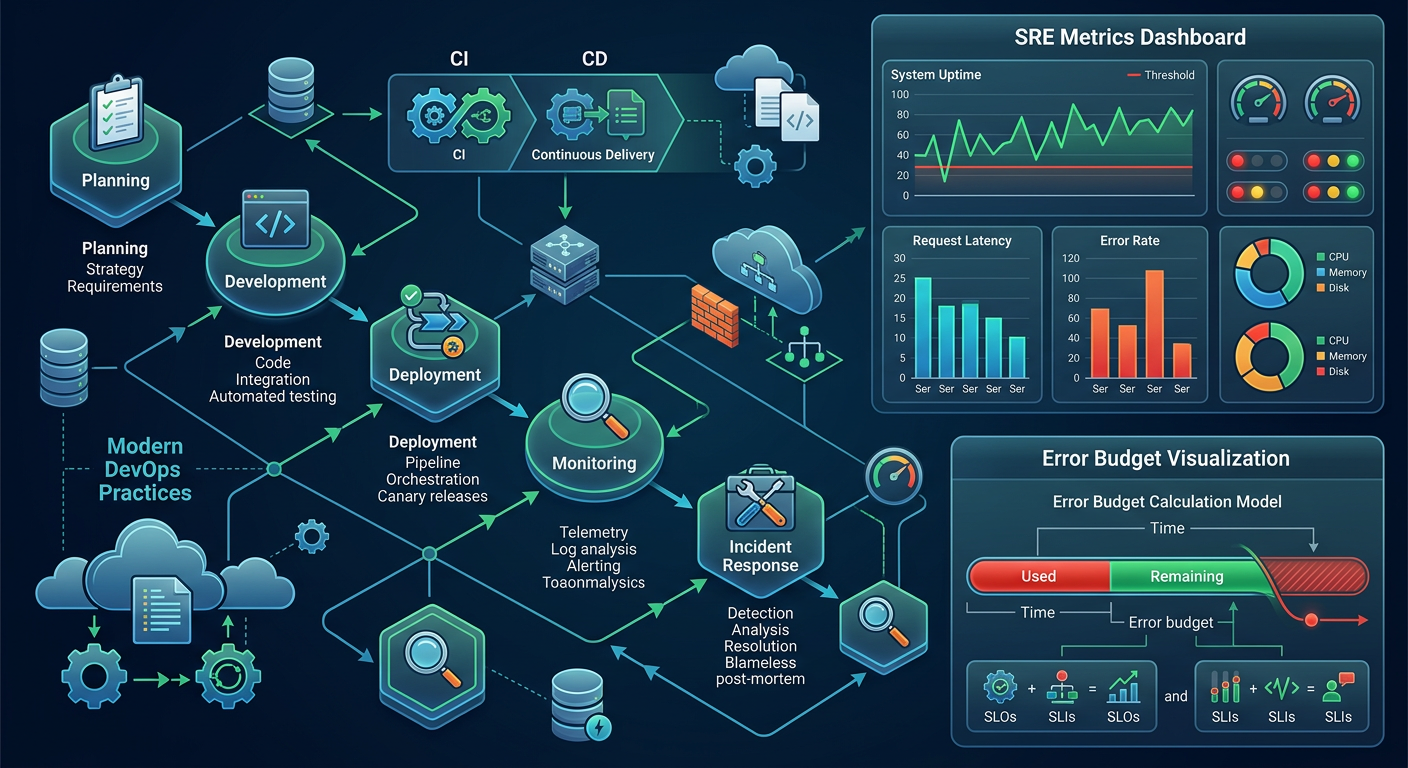
 Verlässliche Cloud-Infrastrukturen entstehen nicht durch reaktiven Support allein, sondern durch sorgfältige Architektur, konsequentes Infrastructure as Code und einen Betrieb, der Probleme frühzeitig erkennt, bevor sie zu Vorfällen werden. Unsere SLAs sind deshalb kein Ersatz für gute Infrastruktur, sondern das vertragliche Fundament einer Partnerschaft, die auf stabilen Systemen aufbaut.
Verlässliche Cloud-Infrastrukturen entstehen nicht durch reaktiven Support allein, sondern durch sorgfältige Architektur, konsequentes Infrastructure as Code und einen Betrieb, der Probleme frühzeitig erkennt, bevor sie zu Vorfällen werden. Unsere SLAs sind deshalb kein Ersatz für gute Infrastruktur, sondern das vertragliche Fundament einer Partnerschaft, die auf stabilen Systemen aufbaut.
